ChatGPT 깔았는데 왜 효과가 미미할까 — 결과가 휘발되는 4가지 자리
에이전틱 워크플로우가 작동하기 시작하면 다음 질문은 결과가 어디에 쌓이는가. 4요소(이벤트 로그·의사결정 로그·인덱스·재활용 루프). 카페 프랜차이즈 본사가 월 보고서 하루를 15분으로 줄인 비결.

에이전틱 워크플로우가 작동하기 시작하면 다음 질문은 — 결과가 어디에 쌓이는가.
매주 같은 일을 처음부터 다시 시작하지 않으려면, 축적 구조 4요소가 박혀야 합니다. 이게 비어있으면 자동화는 자동화 흉내일 뿐이에요.
AWC가 정의한 AX 4 Pillar(에이전틱 워크플로우 실행 프레임 — 후보 식별·분해·에이전트 배치·인계·축적) 중 마지막 단계가 이 글의 주제입니다.
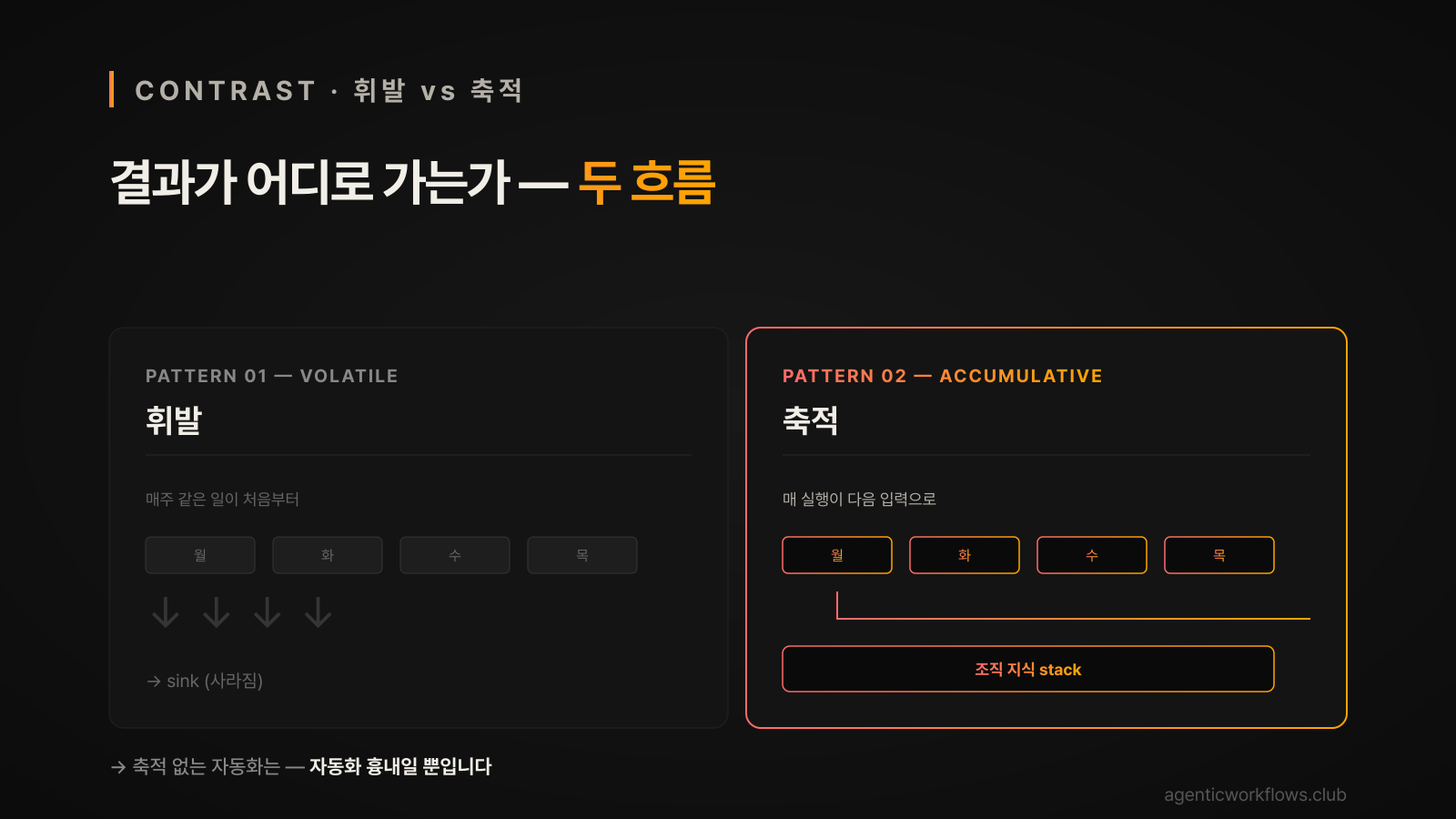
축적이란 무엇인가
축적은 실행 결과와 의사결정 컨텍스트가 사라지지 않고 다음 작업의 입력이 되는 구조입니다.
분해된 단계가 도면이고, 배치가 사람·기계 좌석이고, 핸드오프가 그 사이 흐름이라면 — 축적은 흐름이 끝난 후에 무엇이 남는가예요.
남는 게 없으면 다음 주 같은 일이 다시 시작됩니다.
RAG-only Anti-pattern — 가장 흔한 함정
요즘 가장 많이 보이는 함정. ChatGPT나 RAG 시스템을 깔고 검색·답변만 합니다. 결과는 휘발됩니다.
- 변호사가 어제 판례 리서치한 결과 → 어디에도 안 남음
- SV가 가맹점 방문하고 보고한 내용 → 카톡 채팅에만
- 의뢰인 응대 결정의 이유 → 사라짐
겉보기엔 작동하는 자동화예요. 안 망가져 보입니다. 근데 다음 주 같은 일이 또 들어오면 처음부터 다시. 분해 단계에서 자주 보이는 상태 휘발 패턴의 본격 형태예요.

축적 없는 자동화는 자동화 흉내일 뿐입니다.
축적 구조 4요소
작동하는 축적 구조에는 4가지가 동시에 자리잡고 있어요.
1. 이벤트 로그
실행 결과가 시간·맥락과 함께 자동으로 저장되는 자리. 매출·재고·리뷰·메시지 — 사람 손 거치지 않고 쌓입니다.
2. 의사결정 로그
핸드오프에서 사람이 내린 결정 + 그 이유와 선택지까지 기록. "승인한 결정"만이 아니라 "왜 승인했는지"가 같이 들어가야 다음에 비슷한 케이스에서 참조 가능해요.
3. 인덱스
누적된 데이터를 키워드·카테고리·관계로 검색 가능하게 만드는 자리. 인덱싱 안 된 데이터는 사실상 안 쌓인 거예요. 찾을 수 없으니까.
4. 재활용 루프
누적된 지식이 다음 실행의 입력으로 흐르는 구조. 이상 감지 알림(과거 패턴 + 현재 데이터), 자동 보고서(누적 데이터 자동 집계), 유사 사례 추천(인덱스 검색)이 다 재활용 루프 산출물.

4요소 중 하나라도 빠지면 축적은 작동 안 합니다.
카페 프랜차이즈 본사 — 8개 점포가 한 건물에 있는 것처럼
추상은 그만. 실제 4요소가 자리잡은 모양 보여드릴게요. AWC가 수도권 카페 프랜차이즈 본사(직원 4명·가맹점 8개)에 깐 축적 구조입니다.
4요소 | 카페 프랜차이즈에서의 형태 |
|---|---|
이벤트 로그 | 8개 점포 POS·배달앱·SNS 리뷰 자동 누적 |
의사결정 로그 | SV 방문 보고서 디지털화 + 전 점포 히스토리 |
인덱스 | 통합 검색 (과거 보고서·리뷰·매출 키워드 검색) |
재활용 루프 | 이상 감지 알림 + 월간 보고서 자동 생성 |

이 구조 하나로 결과가 이렇게 바뀝니다.
항목 | Before | After |
|---|---|---|
일 매출 집계 | 카톡 수신 → 엑셀 수동 입력 | POS 자동 집계 |
매출 이상 감지 | 파악 불가 | 전일 대비 30% 하락 시 즉시 알림 |
재고 파악 | 주 1회 전화 확인 | 실시간 트래킹 + 자동 발주 알림 |
신메뉴 반응 | 1–2주 소요 | 실시간 대시보드 |
월간 보고서 | 제작에 하루 소요 | 자동 생성 + 15분 검토 |

대표님 한 분의 표현이 이 구조를 정확히 요약합니다.
"8개 점포가 한 건물에 있는 것 같아요. 뭔가 생기면 바로 알게 되니까, 이제는 가맹점을 믿고 기다리는 게 아니라 우리가 먼저 보고 움직일 수 있어요."
본사 직원은 여전히 4명입니다. 인력을 늘리지 않고 일하는 방식만 바꿨어요. 그게 축적 구조의 힘이에요.
자주 묻는 질문
데이터를 어디에 쌓아야 하나요?
도메인 따라. 매출 데이터는 BI 도구·데이터베이스, 의사결정 로그는 옵시디언·Notion·내부 위키, 비정형 자료는 검색 가능한 저장소. 핵심은 인덱싱 가능한가예요. 카톡 채팅에만 남으면 인덱스 0이라 사실상 안 쌓인 겁니다.
의사결정 로그는 사람이 매번 적어야 하나요?
에이전트가 90% 자동 작성, 사람은 10% 검토. 핸드오프에서 사람이 결정하는 순간 에이전트가 컨텍스트(입력·선택지·결정·시간)를 자동 기록합니다. 사람은 결정 이유 한 줄 정도만 추가합니다.
축적 구조 도입에 얼마나 걸리나요?
워크플로우 1개 기준 2–4주. 데이터 통합·인덱싱·재활용 루프 설계 순서. 도입 후엔 가맹점 수·사건 수·고객 수가 늘어도 추가 인력 없이 확장됩니다.
의사결정 로그를 어떻게 시작해야 하나요?
한 워크플로우의 핸드오프 자리부터 시작하세요. 사람이 결정한 순간을 자동 기록하고, *"왜 이 결정을 했는지"* 한 줄만 추가하는 형태. ==처음엔 옵시디언·노션 한 페이지로 충분합니다.== 한 달 쌓이면 패턴이 보이고, 그때 본격적인 인덱스 구조로 옮기는 순서가 안정적이에요.
데이터가 별로 없는 회사도 축적 구조가 의미가 있나요?
있습니다. 오히려 데이터 없을 때 시작하는 게 더 좋아요. ==처음부터 축적 구조를 짜두면 매주 자동으로 쌓이거든요.== 6개월 후엔 자연스럽게 데이터 자산이 됩니다. 거꾸로 데이터 쌓일 때까지 미루면 1~2년 분량을 사후에 정리해야 해서 비용이 훨씬 큽니다.
인덱스는 어떤 도구로 만들어야 하나요?
도메인 따라. 매출·재고 정형 데이터는 BI 도구(Metabase·Looker·Superset 등), 비정형 문서는 검색 가능한 노션·옵시디언·내부 위키. 핵심은 *키워드 검색이 가능한가*예요. 카톡·이메일에만 남으면 인덱스 0이라 사실상 안 쌓인 겁니다. 도구는 도메인 진단 후 결정합니다.
직원이 "왜"를 적기 귀찮아하면 어떻게 하나요?
==90%는 에이전트가 자동 작성하고, 사람은 한 줄만 추가하는 형태로 세팅하세요.== 핸드오프 시 컨텍스트(입력·선택지·결정·시간)는 에이전트가 자동 기록합니다. 사람은 *결정 이유 한 줄*만 적습니다. 그래도 안 적으면 그 이유 칸이 비어있다는 알림이 다음 핸드오프 때 같이 뜨도록 설계하세요.
데이터가 늘어나면 검색·처리 속도가 느려지지 않나요?
인덱스 설계가 정확하면 데이터 양에 거의 영향받지 않습니다. ==점포·사건·고객이 10배 늘어도 인덱스 검색은 ms 단위 차이.== 느려지는 케이스는 보통 인덱스 없이 풀스캔하는 구조라 그래요. 도입 시 인덱스 키 설계가 6개월 후 검색 속도를 결정합니다.
정리
축적은 결과·결정·맥락이 휘발되지 않고 쌓이는 구조입니다. 이벤트 로그·의사결정 로그·인덱스·재활용 루프 4요소가 동시에 자리잡아야 작동해요.
이 글이 다룬 자리는 AWC가 정의한 AX 4 Pillar의 마지막 단계 — Knowledge Accumulation입니다. 후보 식별·분해·에이전트 배치·인계·축적, 5단계가 다 살아있는 워크플로우만 작동해요. 하나라도 빠지면 어딘가에서 새고, 사고 나고, 매주 처음부터 다시 시작합니다.
대표님 매주 반복 업무 5개 펼쳐놓고 1번부터 다시 보세요. 후보가 보이면, 거기서부터 시작입니다.
작성: Bruce Choe · agenticworkflows.club
함께 보면 좋은 글
읽은 다음
아이디어를 실행 구조로 바꿔보세요
업무별 Trigger, Agent, Human Checkpoint가 정리된 Workflow를 확인할 수 있습니다.